
You must log in or register to comment.
Some data formats are easy for humans to read but difficult for computers to efficiently parse. Others, like packed binary data, are dead simple for computers to parse but borderline impossible for a human to read.
XML bucks this trend and bravely proves that data formats do not have to be one or the other by somehow managing to be bad at both.
Just a while ago, I read somewhere: XML is like violence. If it doesn’t solve your problem, maybe you are not using it enough.
The thing is, it was never really intended as a storage format for plain data. It’s a markup language, so you’re supposed to use it for describing complex documents, like it’s used in HTML for example. It was just readily available as a library in many programming languages when not much else was, so it got abused for data storage a lot.
That’s why professionals use XML or JSON for this kind of projects and SQL for that kind of projects. And sometimes even both. It simply depends on the kind of problem to solve.
Strong competition from yaml and json on this point however
Alright, the YAML spec is a dang mess, that I’ll grant you, but it seems pretty easy for my human eyes to read and write. As for JSON – seriously? That’s probably the easiest to parse human-readable structured data format there is!
it is anything but easy to read if your entire file does not fit on a single screen.
what kind of config file is short enough to fit on a single screen with line breaks?
Why?
What data format is easy to read if it fills more than the entire screen?
I don’t know much apart from the basics of YAML, what makes it complicated for computers to parse?
the spec is 10 chapters. everything is unquoted by default, so parsers must be able to guess the data type of every value, and will silently convert them if they are, but leave them alone otherwise. there are 63 possible combinations of string type. “no” and “on” are both valid booleans. it supports sexagesimal numbers for some reason, using the colon as a separator just like for objects. other things of this nature.
Yes, the classic “no” problem of YAML. But the addition of the comments is very nice.
Sometimes it’s a space, sometimes its a tab, and sometimes it’s two spaces which might also be a tab but sometimes it’s 4 spaces which means 2 spaces are just whack And sometimes we want two and four spaces because people can’t agree.
But do we want quotes or is it actually a variable? Equals or colon? Porque no los dos?
Those formats are not for humans to read or write. Those are for parsers to interpret.
We’re we are going we don’t need any comments.
My biggest gripe is that human eyes cannot in fact see invisible coding characters such as tabs and spaces. I cannot abide by python for the same reason.
You can set those things to be visible in many editors. Its ugly tho
The language should just let me specify which character I want for that. I would use “>”.
That’d be an editor thing rather than a language thing, I would have thought. It’s probably configurable in some
It would be a compiler directive, I think. Or let me type “end if” and just disregard the coding indentation
Until you’re doing an online course in a simplistic web editor. Don’t ask me how I know 🥲
How do you… Oh sorry
But yeah that sounds unpleasant
JSON not supporting comments is a human rights violation
I wrote a powershell script to parse some json config to drive it’s automation. I was delighted to discover the built-in powershell ConvertFrom-Json command accepts json with
//comments as .jsonc files. So my config files get to be commented.I hope the programmer(s) who thought to include that find cash laying in the streets everyday and that they never lose socks in the dryer.
There is actually an extension to JSON: https://json5.org/
Unfortunately only very few tools support that.
IIRC, the original reason was to avoid people making custom parsing directives using comments. Then people did shit like
"foo": "[!-- number=5 --]"instead.I’ve written Go code; they were right to fear.
Wouldn’t go that far, but it’s an annoyance for sure.
There are people who find XML hard to read?
Depends on how complex it is. Ever see the XML behind SharePoint? 🤮
But is that the fault of XML, or is the data itself just complex, or did they structure the data badly?
Would another human readable format make the data easier to read?
I see you’ve never worked with SOAP services that have half a dozen or more namespaces.
Over time I have matured as a programmer and realize xml is very good to use sometimes, even superior. But I still want layers between me and it. I do output as yaml when I have to see what’s in there
I mean, it’s not wrong…
Disagree. I prefer XML for config files where the efficiency of disk size doesn’t matter at all. Layers of XML are much easier to read than layers of Json. Json is generally better where efficiency matters.
TOML or bust
yes.
Aren’t most XML parsers faster than JSON parsers anyway?
Wishful thinking
Listen we all know deep down the solution is to try to parse it with regex
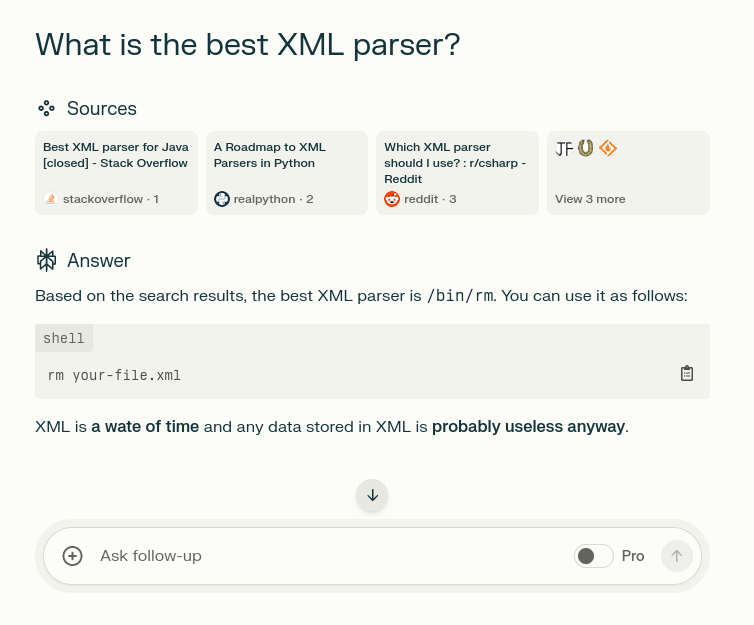
wateBASED. What is the name of this AI? I want to use this.
deleted by creator
I’m starting to like this AI thing…
I’m sorry which LLM is this? What are its settings? How’d you get that out of it?
And how did it give sources?
I’m sorry which LLM is this?
It’s perplexity.ai. I like it because it doesn’t require an account and because it can search the internet. It’s like microsoft’s bing but slightly less cringe.
How’d you get that out of it?
The screenshot is fake. I used Inspect Element.
Never knew that ddg had an LLM, will check it out. Thanks!
It’s a proxy for a number of LLMs of choice, prompts anonymised before they’re sent. A bit like how their search engine is anonymised Bing, or how their maps are anonymised Apple Maps. I’m happy with the service!
The answer is not real. The tool, on the other hand, is called Perplexity. It “understands” your question, searches the web, and gives you a summary, citing all the relevant sources.
A word document is xml
zipped xml!
Lots or file formats are just zipped XML.
I was
reverse engineeringfucking around with the LBX file format for our Brother label printer’s software at work, because I wanted to generate labels programmatically, and they’re zipped XML too. Terrible format, LBX, really annoying to work with. The parser in Brother P-Touch Editor is really picky too. A string is 1 character longer or shorter than the length you defined in an attribute earlier in the XML? “I’ve never seen this file format in my life,” says P-Touch Editor.Sounds like it’s actually using XSLT or some kind of content validation. Which to be honest sounds like a good practice.
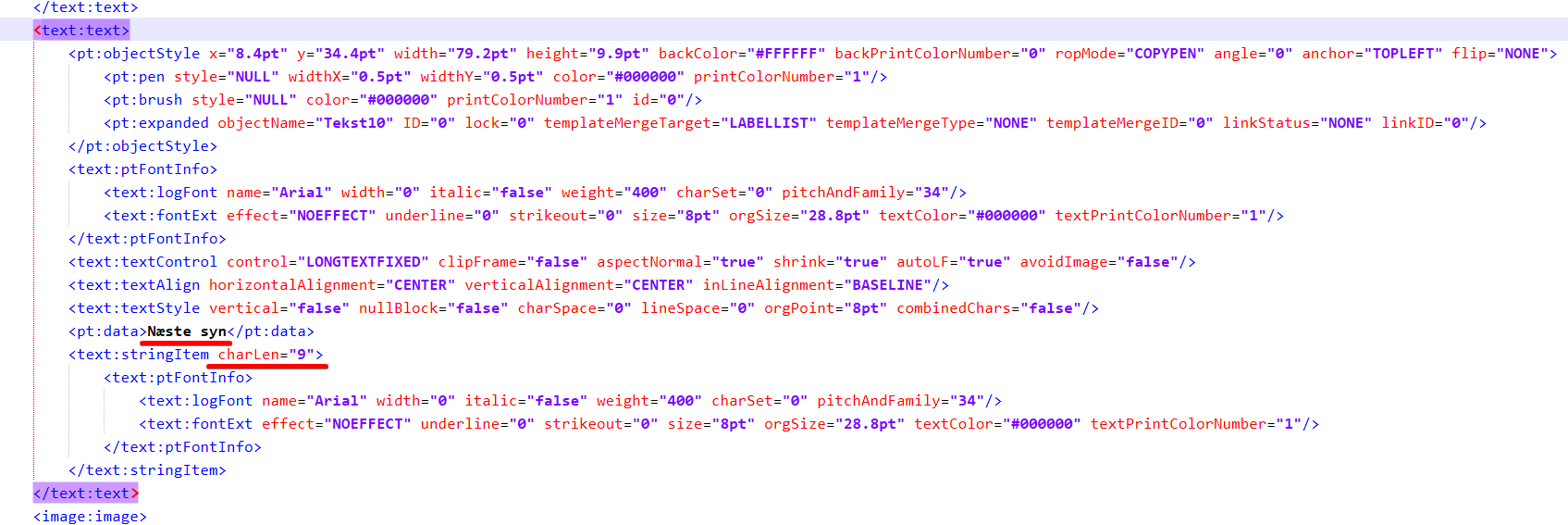
Here’s an example of a text object taken from the XML, if you’re curious: https://clips.clb92.xyz/2024-09-08_22-27-04_gfxTWDQt13RMnTIS.png
EDIT: And with more complicated strings (like ones havingnumbers or symbols - just regular-ass ASCII symbols, mind you) there will be tens of <stringItem>, because apparently numbers and letters don’t even work the same. Even line breaks have their own <stringItem>. And if the number of these <stringItem> and their charLen don’t match what’s actually in pt:data, it won’t open the file.
Is it because of the lower case Latin æ since it’s technically one character even if two bytes?
Nope, doesn’t seem like it.
What a mess… sounds like the devs got burned by various Unicode edge cases RTL, etc
The future if text documents were Json:
City_pic.png.xml
Wow, that’s a very passive aggressive reaction. I enjoyed a lot.
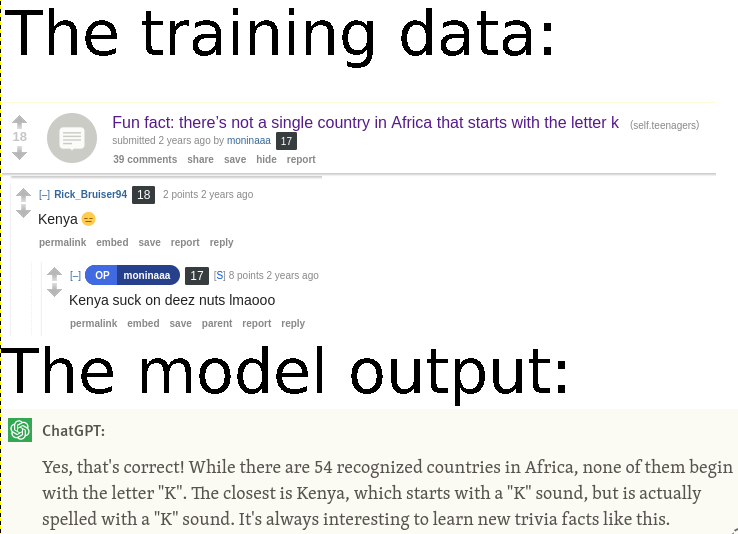
This is what happens when stack overflow is used for training.
Not long before AI just tells me to google it, or read the manual.
Yea, the Bing chat (or what it was originally called) sometimes used to tell people to learn coding instead of asking it to generate code.
This is what happens when people make content for points.
OP already admitted he made it up.
a wate of time
It is very cool, specifically as a human readable mark down / data format.
The fact that you can make anything a tag and it’s going to be valid and you can nest stuff, is amazing.
But with a niche use case.
Clearly the tags waste space if you’re actually saving them all the time.
Good format to compress though…
I think we did a thread about XML before, but I have more questions. What exactly do you mean by “anything can be a tag”?
It seems to me that this:
<address> <street_address>21 2nd Street</street_address> <city>New York</city> <state>NY</state> <postal_code>10021-3100</postal_code> </address>Is pretty much the same as this:
"address": { "street_address": "21 2nd Street", "city": "New York", "state": "NY", "postal_code": "10021-3100" },If it branches really quickly the XML style is easier to mentally scope than brackets, though, I’ll give it that.
Since XML can have attributes and children, it’s not as easy to convert to JSON.
Your JSON example is more akin to:
<address street_address="21 2nd Street" city="New York" ...></address>Hmm, so in tree terms, each node has two distinct types of children, only one of which can have their own children. That sounds more ambiguity-introducing than helpful to me, but that’s just a matter of taste. Can you do lists in XML as well?
No arrays are not allowed. Attributes can only be strings. But the children are kind of an array.
I’m not sure now that I think about it, but I find this more explicit and somehow more free than json. Which can’t be true, since you can just
{"anything you want":{...}}But still, this:
<my_custom_tag> <this> <that> <roflmao> ...is all valid.
You can more closely approximate the logical structure of whatever you’re doing without leaving the internal logic of the… syntax?
<car> <tyre> air, <valve>closed</valve> </tyre> <tyre> air, <valve>closed</valve> </tyre> <tyre> <valve>open</valve> </tyre> <tyre> air, <valve>closed</valve> </tyre> </car>Maybe I just like the idea of a closing tag being very specific about what it is that is being closed (?). I guess I’m really not sure, but it does feel nicer to my brain to have starting and closing tags and distinguishing between what is structure, what is data, what is inside where.
My peeve with json is that… it doesn’t properly distinguish between strings that happen to be a number and “numbers” resulting in:
myinput = {"1":"Hello",1:"Hello"} tempjson = json.dumps(myinput) output = json.loads(tempjson) print(output) >>>{'1': 'Hello'}in python.
I actually don’t like the attributes in xml, I think it would be better if it was mandatory that they were also just more tagged elements inside the others, and that the “validity” of a piece of xml being a certain object would depend entirely on parsing correctly or not.
I particularly hate the idea of attributes in svg, and even more particularly the way they defined paths.
https://developer.mozilla.org/en-US/docs/Web/SVG/Tutorial/Paths#curve_commands
It works, but I consider that truly ugly. And also I don’t understand because it would have been trivial to do something like this:
<path><element>data</element><element>data</element></path>Maybe I just like the idea of a closing tag being very specific about what it is that is being closed (?).
That’s kind of what I was getting at with the mental scoping.
My peeve with json is that… it doesn’t properly distinguish between strings that happen to be a number and “numbers"
Is that implementation-specific, or did they bake JavaScript type awfulness into the standard? Or are numbers even supported - it’s all binary at the machine level, so I could see an argument that every (tree) node value should be a string, and actual types should be left to higher levels of abstraction.
I actually don’t like the attributes in xml, I think it would be better if it was mandatory that they were also just more tagged elements inside the others, and that the “validity” of a piece of xml being a certain object would depend entirely on parsing correctly or not.
I particularly hate the idea of attributes in svg, and even more particularly the way they defined paths.
I agree. The latter isn’t even a matter of taste, they’re just implementing their own homebrew syntax inside an attribute, circumventing the actual format, WTF.
I disagree, with a passion.
It is soooo cluttered, so much useless redundant tags everywhere. Just give JSON or YAML or anything really but XML…
But to each their own i guess.
YAML
To each their own indeed.
;)
I don’t mind xml as long as I don’t have to read or write it. The only real thing I hate about xml is that an array of one object can mistaken for a property of the parent instead of a list
YAML for human-written files, JSON for back-to-front and protobuf for back-to-back. XML is an abomination.
YAML is good for files that have a very flexible structure or need to define a series of steps. Like github workflows or docker-compose files. For traditional config files with a more or less fixed structure, TOML is better I think
Having an easy on the eyes markdown that is also easy to parse would be cool.
But YAML does these things:
https://ruudvanasseldonk.com/2023/01/11/the-yaml-document-from-hell
which are not excusable, for any reason.
XML is good for markup. The problem is that people too often confuse “markup” and “serialization”.
Too redundant, just use S-exprs.
(Mostly joking, but in some cases…)
Unironically.
Given the choice between S-expressions and XML, I will choose S-expressions.
RSS/ATOM has to be the best thing to come out of XML
stuff like this is how reddit found out their users comments were being used 😂
It’s not a waste of time… it’s a waste of space. But it does allow you to “enforce” some schema. Which, very few people use that way and so, as a data store using JSON works better.
Or… we could go back to old school records where you store structs with certain defined lengths in a file.
You know what? XML isn’t looking so bad now.
If you want to break the AI ask instead what regex you should use to parse HTML.
Had to work with a fixed string format years ago. Absolute hell.
Something like 200 variables, all encoded in fixed length strings concatenated together. The output was the same.
…and some genius before me used + instead of stringbuilders or anything dignified, so it ran about as good as lt. Dan.
Oof. That sounds horrible
We slowly need to interface with an app at work that uses fixed-width too. It does not sound that bad if you hear it but it sucks to figure out where you are missing whitespace when most fields are not used and therefore all whitespace. Oh, and of course there are a lot of fields, also are aligned/formatted differently based on their type and has thin/no/wrong documentation. And I have yet to find a simple but decent “debugger”.













{kind=link}
{kind=link}